
In the previous post, we talked about what data structures are. We learned that a linked list is a type of data structure, and we learned why they were important. We particularly looked at singly linked lists as a type of linked list, and we saw some of its usage and operations. Even though singly linked lists have their use in the real world, chances are you will find doubly linked lists easier to implement, more practical and have more real world use. One issue you might have noticed with singly linked lists is that it only has a reference to the next node (or next pointer). This makes it harder to find what the previous node is. We had to write some pretty length code just to find the previous node. The doubly linked list is a type of linked list that has a next and previous properties on the node (pointers), making it very easy to enumerate the node collections in any direction (forwards or backwards). This means we can navigate in both directions. Let us start from the top. Imagine you have a node collection with one node ( like we did from the previous post)
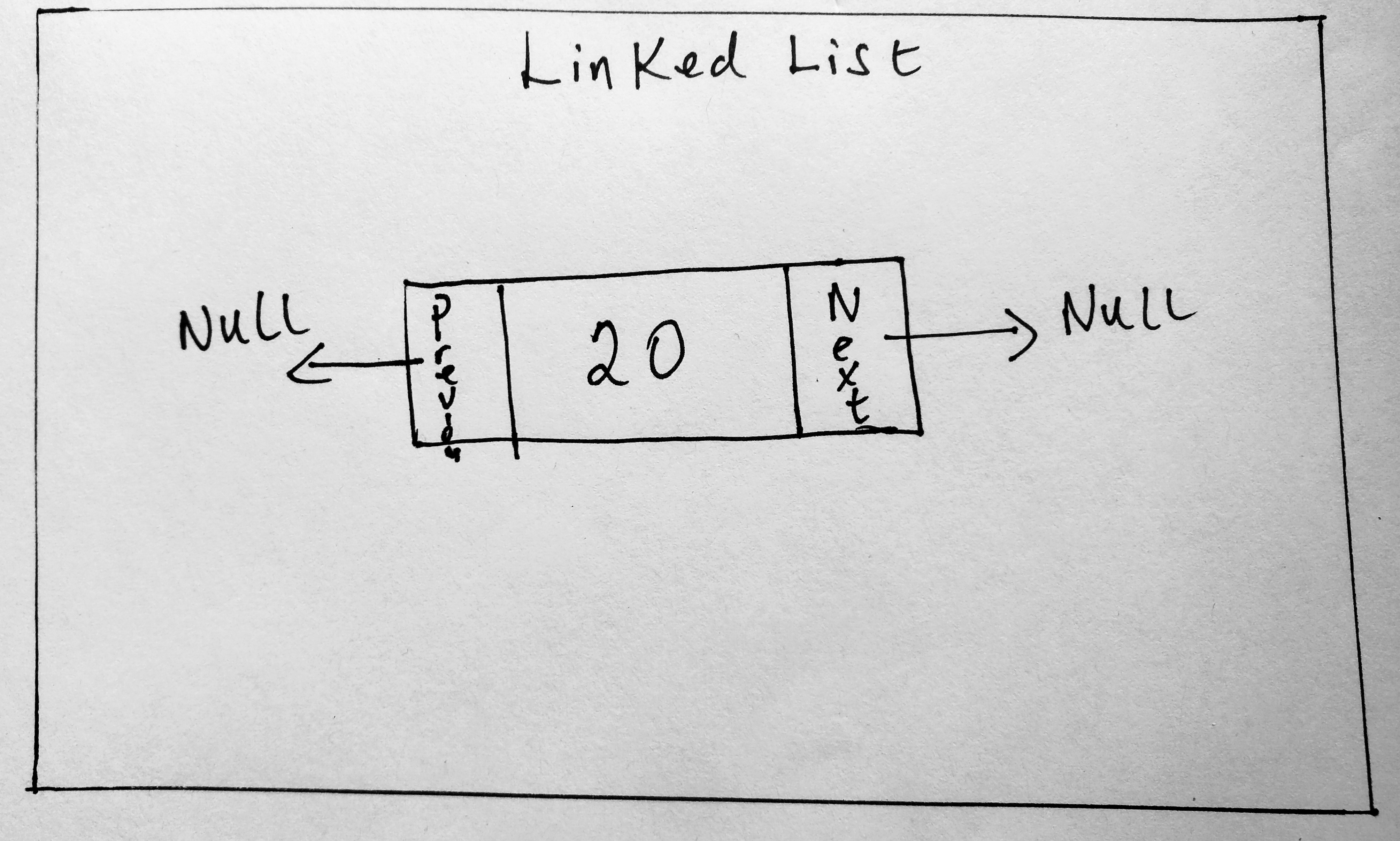
In this image you we only one node in the collection. However notice that our linked list node now has a new property! This property is a pointer to a previous node in the collection if it exists (if not, its set to null). If you haven’t downloaded the source files from the previous post already, you can download it HERE (look for the doubly_linkedlist.js file). Since i have laid the foundation for linked lists in the previous post, i will be skipping over a lot of theory in this post, just so we get straight to using doubly linked links. I will only be covering things i have not discussed. Below you will find a doubly linked list collection with a head and tail.
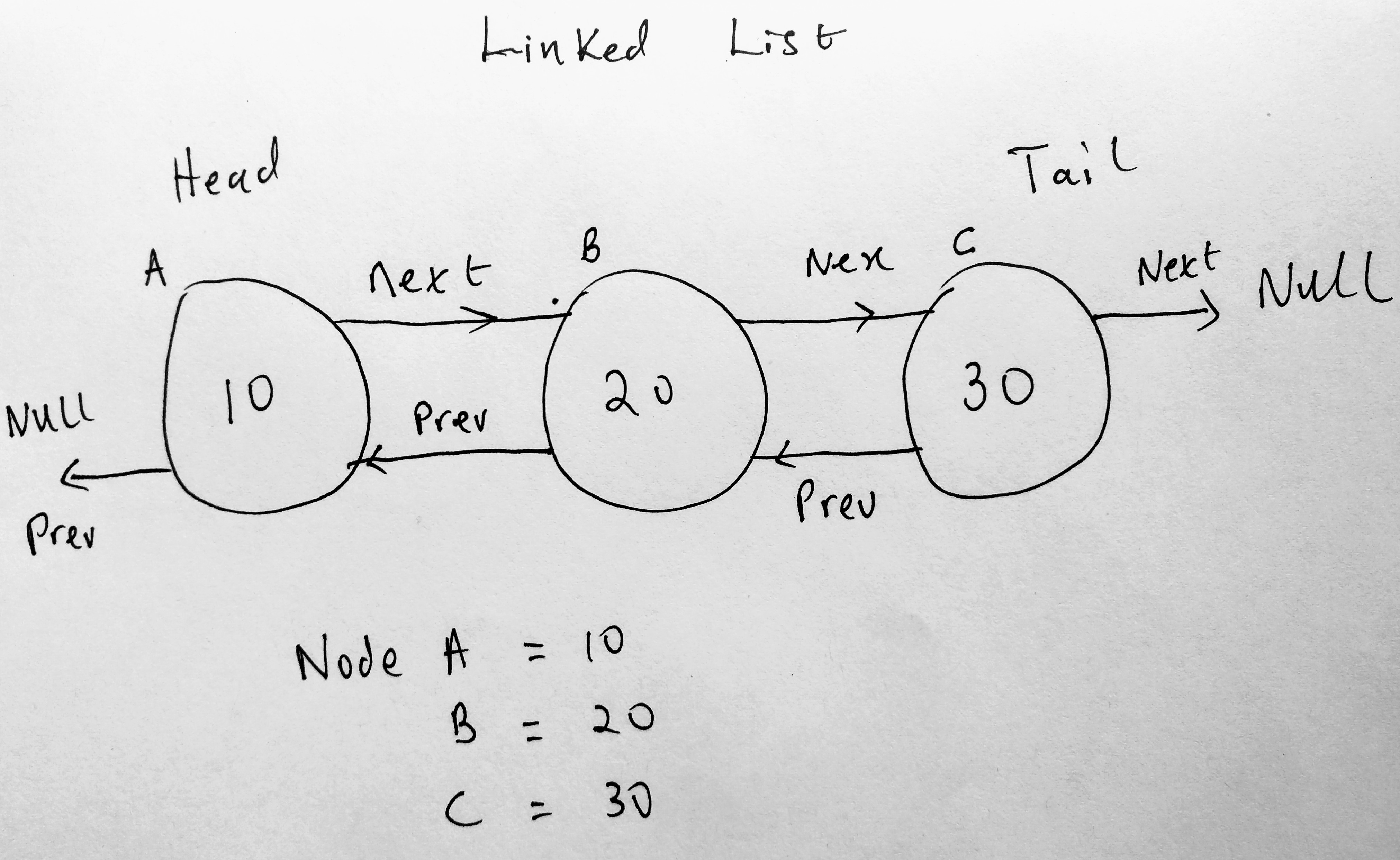
Notice how this differs from a single linked list collection. The head now has a previous pointer. The same applies to Nodes which exists in the middle of the collection. The point here is every node will know what its previous node is (even if its null). Let us now update the node class.
The Node and Doubly Linked List Class
See the Pen The Node and Doubly Linked List Class by kofi (@scriptonian) on CodePen.
The doubly linked list class is just an update to the singly linked list class. They are almost identical, with the exception of the new previous pointer property added to the constructor function. PLEASE NOTE: even though i have listed all the helper classes in this post, we will not be covering methods that don’t require code updates. Some of these methods are indexOf, find, display, size, etc. If you don’t find a new implementation here, then you can find it on the previous post. However we will be talking about new methods OR update existing methods that need it (because the node has a new previous property). If you see method here that is the same as that of a singly list class, then its just to give better clarity.
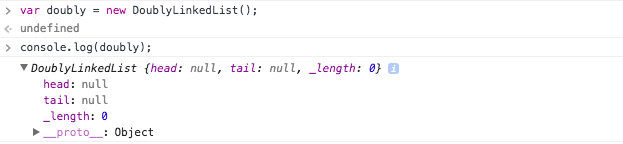
Jumping into our console, we can create a new doubly linked list object and see its properties.
And the node constructor
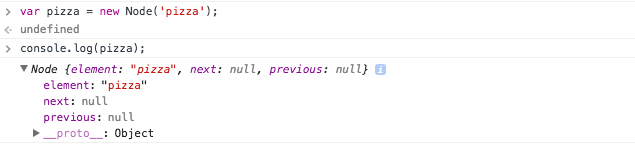
See that the node has both the next and previous pointers as well as the name of the node (pizza).
Linked List Operations
Add to head
Let us jump into our linked list operations. If you don’t know what these are i highly suggest you read the previous post. We will start by writing our adding to head of the linked list functionality. Again, we will be updating our singly linked list implementation since all a doubly linked list is an enhancement to a singly linked list. Before we do that, lets look at a new diagram.
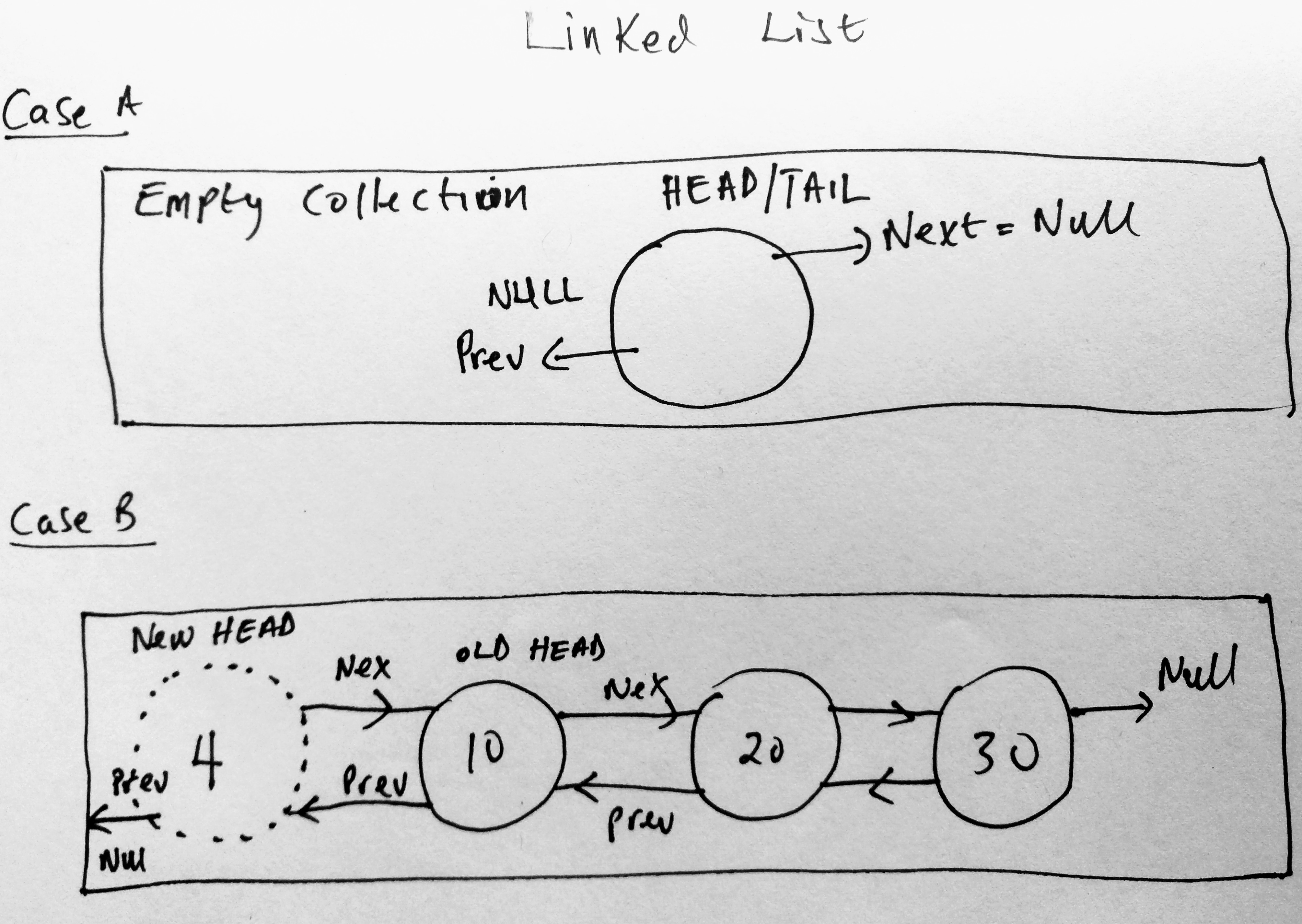
In the previous post i mentioned that when you add a node to a collection, there are 2 possible conditions that might be in place. In Case A, we are adding to a collection that is already empty. In which case the head and tail are both the newly added node. In the second case, there is already a head in the collection. In such a case, we have to update the pointers of the already existing head, as well as the new node(to be the new head). The previous pointer of the head (which was null), will now be pointed to the new node (since that is the new head). We also update the head property of the linked list to be the new node. Here is our newly updated addToHead method.
See the Pen Doubly Linked List – Add To Head by kofi (@scriptonian) on CodePen.
If you have already downloaded the source code for this project, you will find better code commenting. I have made comments on just about every line of code. For visual clarity i have removed them from this post to make it easier to read. The code above represents exactly what we spoke about adding a node to the head of the linked list operation. Compared to our previous implementation(singly linked list), we added one line of code (pointing the previous pointer of the old head to point to the newly added node). Using the console, lets test what we have so far. We will create a new doubly linked list, and add a new node to it. Next we will inspect the linked list object.
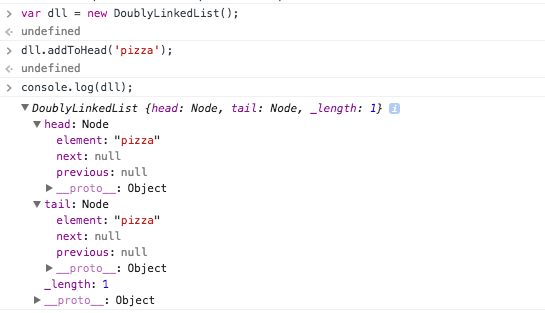
Notice that we get the expected results. We create a DoublyLinkedList object and add a node to it using the addToHead method. In our linked list collection, we have one node ( see length property). Our head and tail are both the pizza object (because we have only one node in the collection). What happens when we add another node to the collection? What would you expect to happen? We since we are using the addToHead method, the current heads pointers will be updated to point to the new node, and the new nodes next will point to the old head. Lets see this in action by adding a tomato vegetable to our collection.
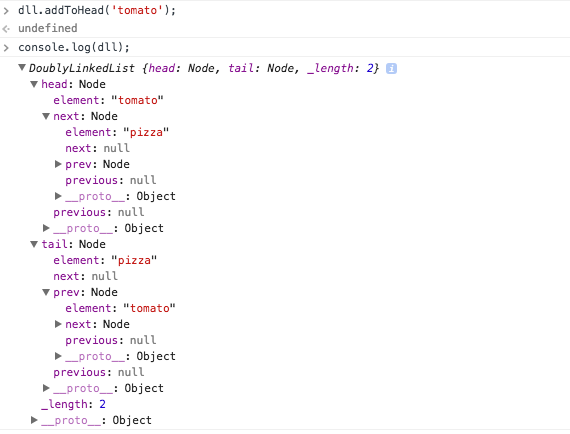
We added a tomato to our collection. We can see our length has incremented to 2 and the head is pointing to the tomato node. Our tail is now the pizza. Notice that in both the head and the tail we can introspect our next and previous pointers within those nodes. For example, if we look at the tail node, we can see it has a previous of tomato (which makes total sense). We can keep adding to the head of the the node collection and get this chain setup for us (one node linking to the next/previous). Lets do that,
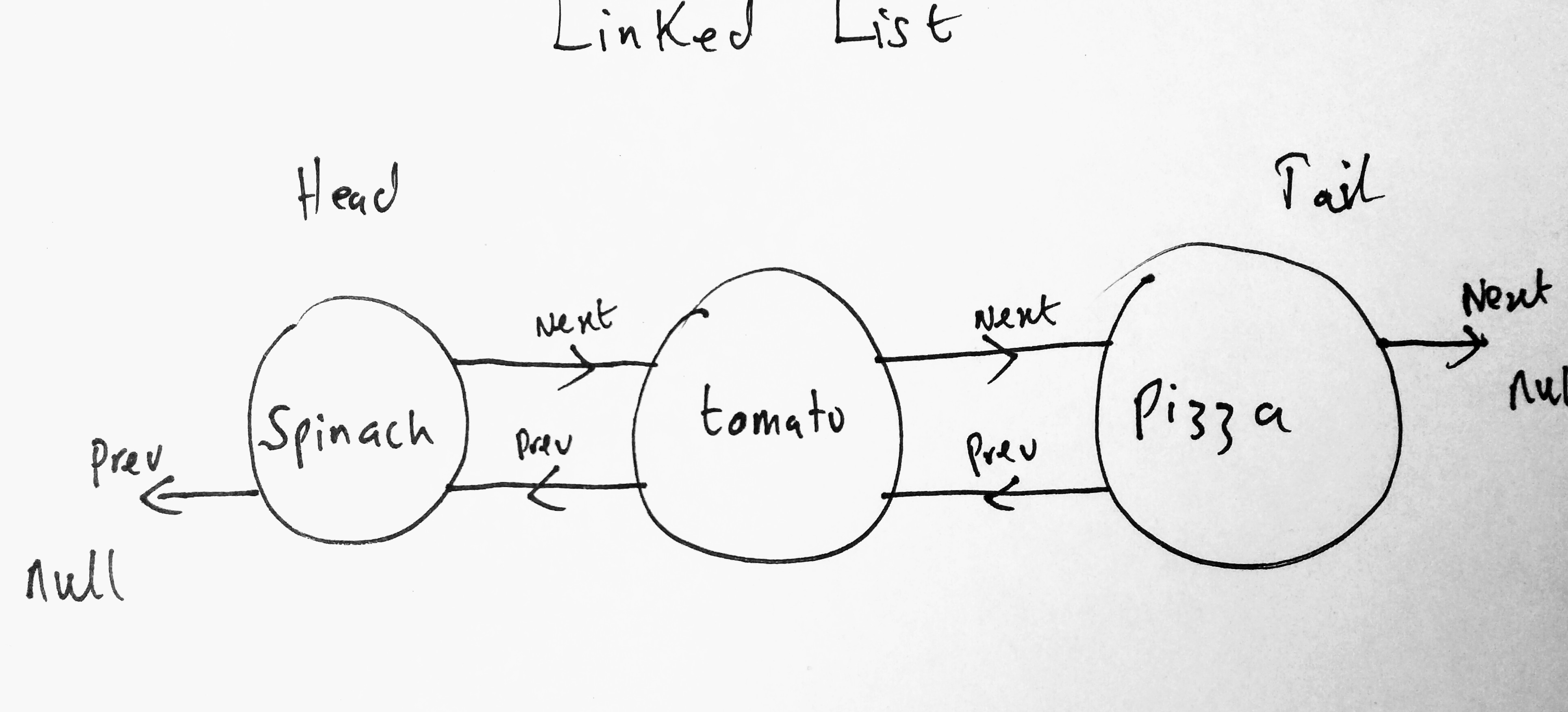
We are going to spinach to the head of our node list. When that happens you can see that tomato will be in the middle. It will have a next of pizza and a previous of spinach.
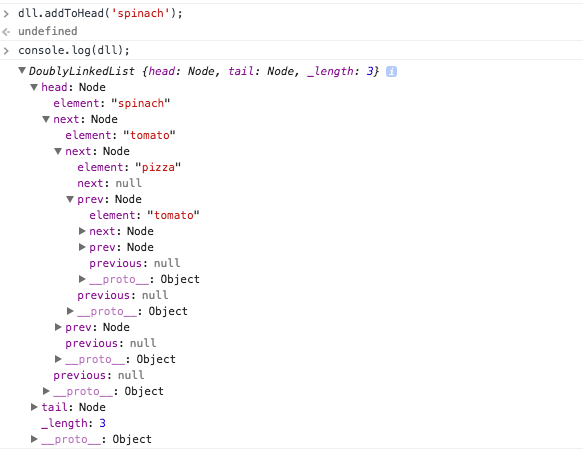
The above diagram speaks for itself. You can see tomato’s next is pizza and its previous is spinach. I would suggest copying and pasting the code in the console and testing it out yourself. Create a DoubleLinkedList object and use the addToHead method to add items to it. Then inspect it yourself in a browser.
Add to tail
You already learned that adding to tail is very similar to adding to head, but lets see some of the code changes we need to make when dealing with doubly linked lists. First lets look at the diagram as it makes it easier code the solution.
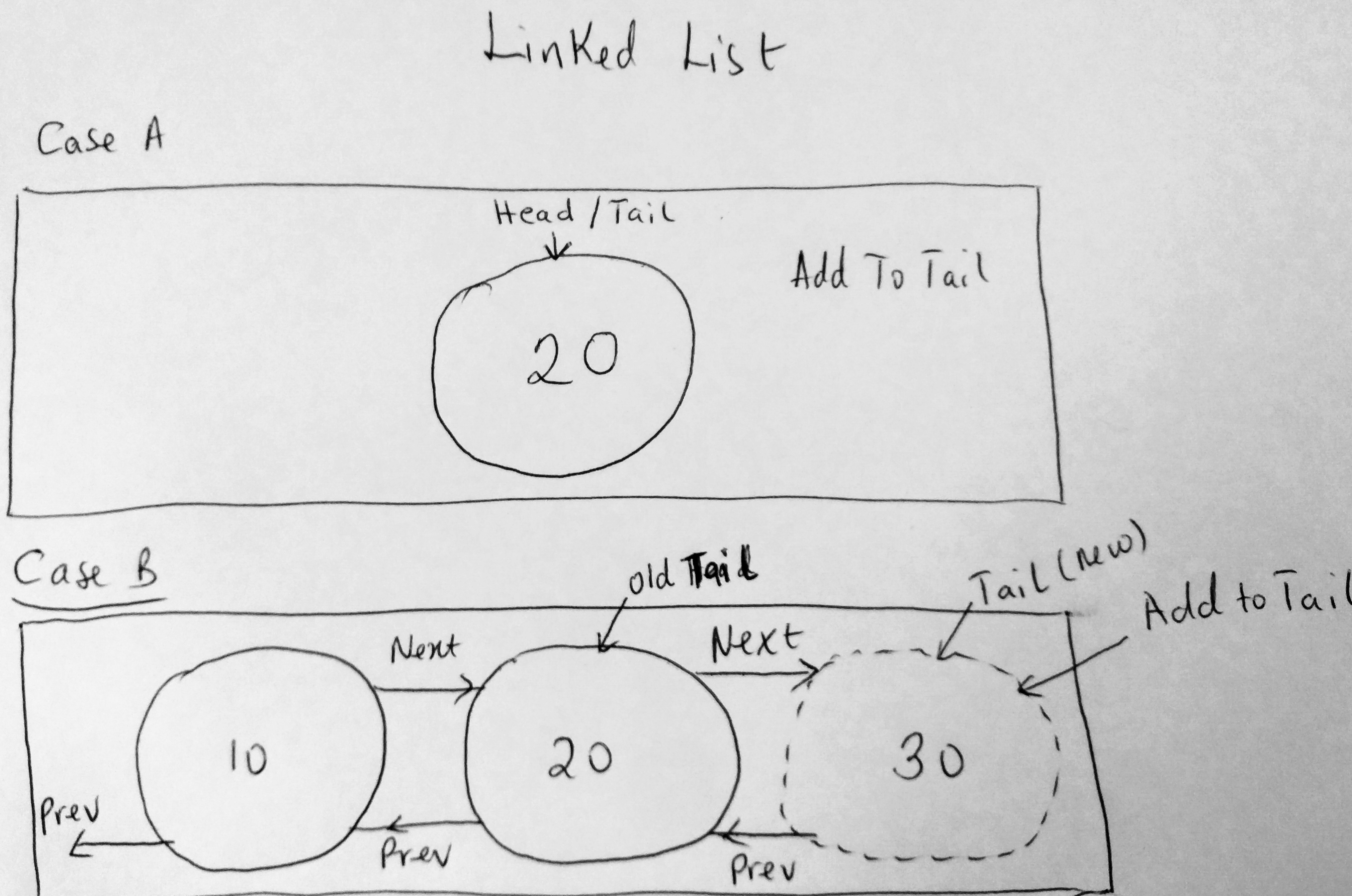
Just like add to head, add to tail also has two scenarios to check when using this operation: whether there are nodes(Case B) in the collection, or there aren’t (Case A). We have already talked about Case A. When adding to the tail of a collection of nodes, you have to update the next pointer of the old tail to point to the new node, and update the previous pointer of the new node to point to the old tail. Here is the code.
See the Pen Doubly Linked List Add to Tail by kofi (@scriptonian) on CodePen.
Lets test our add to tail code!
See the Pen Add To Tail – Testing Code by kofi (@scriptonian) on CodePen.
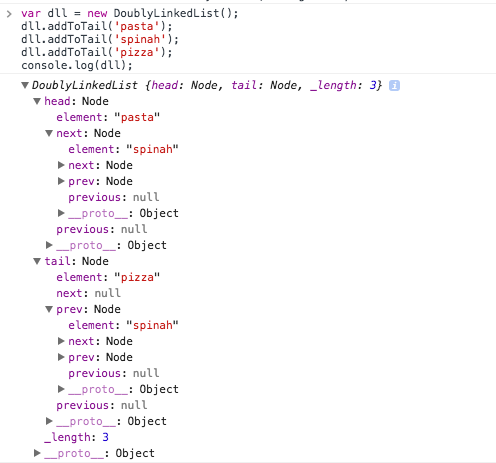
Beautiful isnt it. The last node we added to our collection is the pizza object. The prev node to pizza is spinach. Since pasta was the first thing we added to the tail, it got pushed to the first item in the collection (the head). The next node to the head is spinach. Lets move on.
Removing the head or tail node
Now that we know how to add to the head or tail, lets see how we remove them in a doubly linked list implementation. In the remove head and tail section of a singly list, we say that it wasnt easy to do this, especially for remove tail (we didnt have a pointer to the previous node). The only way to do that then was to traverse the entire list to find that node was. Which is not best for our application performance. However since we are upgrading our linked list, we will notice its so much easy to remove the tail now. Lets start with a diagram.
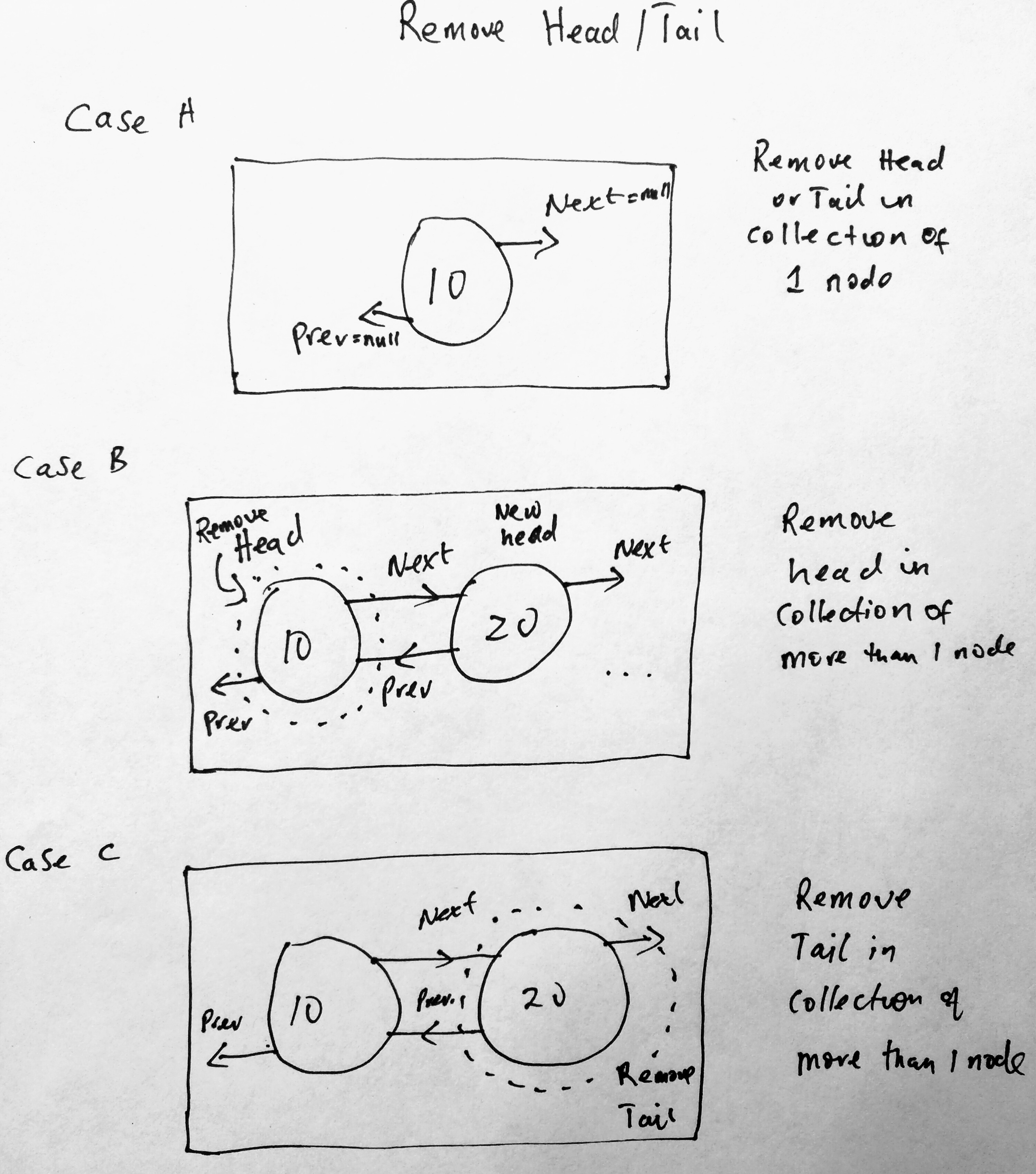
OK, what do we have here in our diagram. To remove the head or tail from a doubly linked list collection, there are some possible scenarios we must encounter. The first is whether our collection has a single node in it, in which case there is only one node to remove. However if there is a collection of node, when we remove the head we have to update the prev and next pointers of the new head. In case A and B above you can see how we could do this. If we remove the head, we must point the new head to the old heads next node as well as update the next and previous of the new head. The same for case C. Lets see this in code.
See the Pen Remove Head or Tail from Doubly Linked List by kofi (@scriptonian) on CodePen.
The nice thing to notice here is that in the singly linked list implementation, we have to write a findPrevious method which returned the previous node of an item. But not this time!
insert()
Let us update our insert() method. We use it to insert a node into any position within our collection. We will implement insert differently this time. In the singly linked list implementation, we used the find helper method to find the name of the node we want to insert after and updated the next pointer. We will update this code (for those who like that method), but we will implement a new insert method as well. Why? The reason is it returns the first instance of the node you are looking for. For example, if there were two names by had the same values, the insert methods find would return the first found node. We want to be able to specify the index to which to insert. This makes it a little bit more flexible. We can pass in the position number to insert, instead of the name. First here is the updated insert method.
See the Pen Doubly Linked List insert() – Method 1 by kofi (@scriptonian) on CodePen.
I also wanted to show give you a little visual on what happens when you insert a node into a doubly linked list collection.
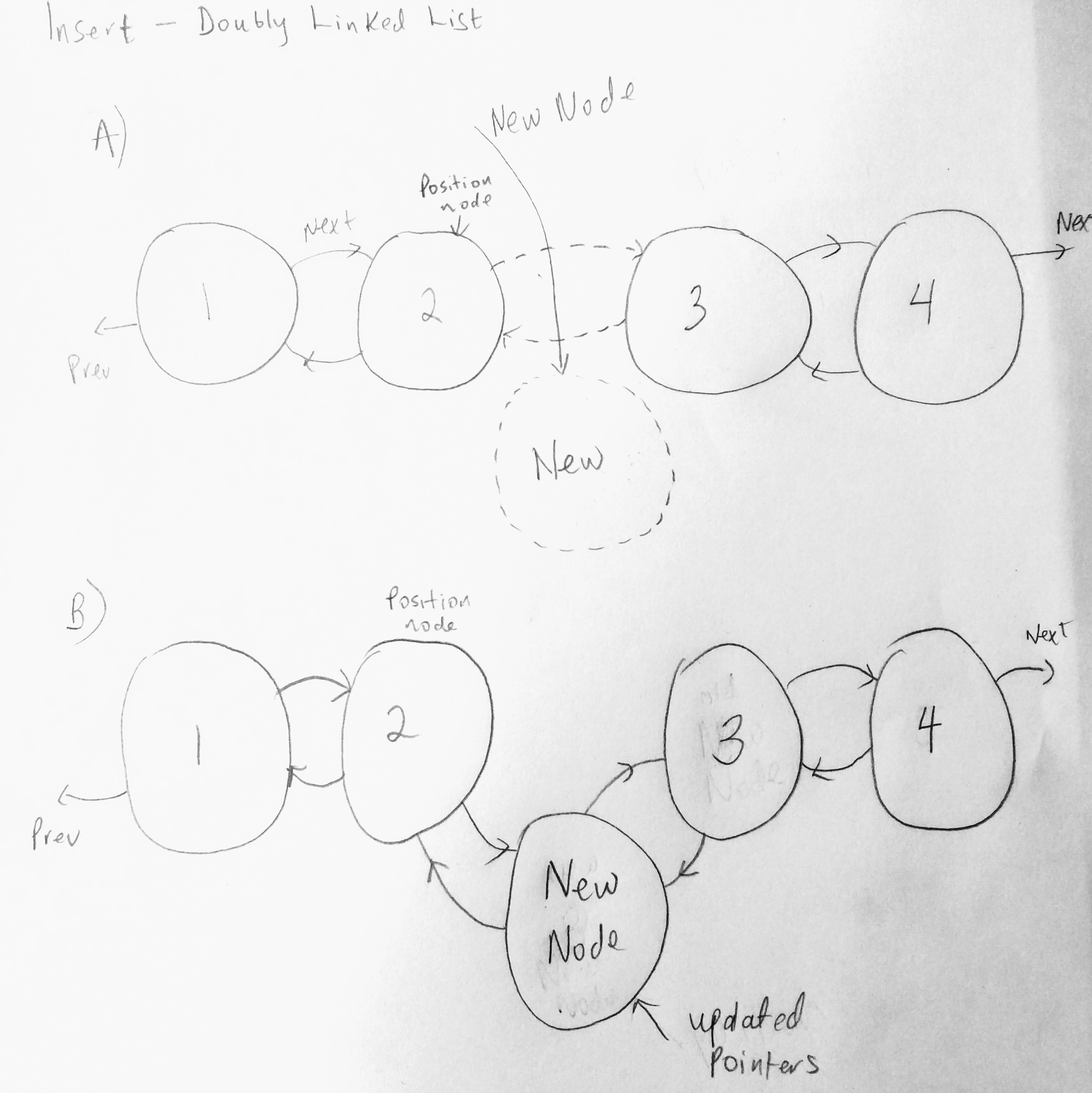
Pay particular attention to the before and after pointers. The new node is added first and then pointers are updated. If you can trace what pointer links where (given the position node), then writing the code becomes a piece of cake. For eg.
a) the new nodes next pointer now becomes the position nodes next pointer
b) the new nodes prev pointer is now the position node
c) the next pointer of the position node now becomes the new node
Don’t forget to checkout the code on github to see code commenting. Now lets write a more flexible insert method.
See the Pen qmzbZB by kofi (@scriptonian) on CodePen.
Here we have our new insert function (enhancedInsert). Instead of passing in the name of the node where we want to do our insertion, we pass in the index instead (Note: The position here is the index). This is more flexible and we can avoid things like have the insert happen in locations where nodes have the same values. We tell it exactly where the new node should be inserted. Lets test our new insert
See the Pen Testing Enhanced Insert by kofi (@scriptonian) on CodePen.
We create a new doubly linked list and add some nodes to it using some of our helper methods. Notice that there are two Tani’s in our list. In our first implementation of insert, if we wanted to insert any node after the second two it wouldnt work. This is because the insert happens on the first node that is found. However with our enhanced implementation we specify exactly where we want it to happen. Looking at our console we see this
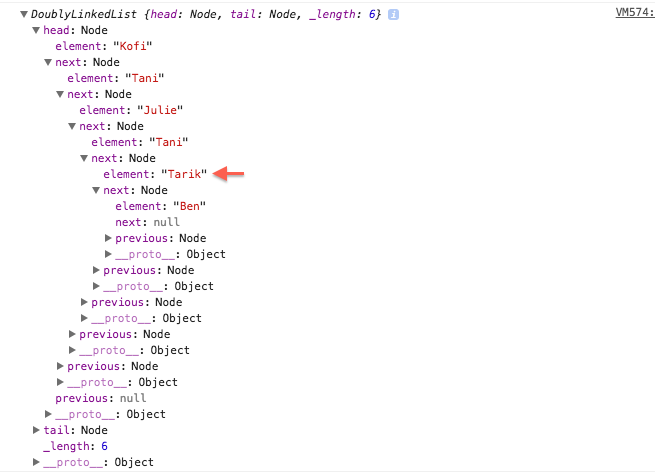
Notice that Tarik is inserted right after the second Tani and not the first. This would not have been possible with our first implementation.
removeAt()
The last thing we will do in this post is learn how to remove any node at any index. In the previous post (singly linked list), we learned how to do this. But we can write a much more flexible function. In the last implementation we called the remove function which also called the removeAt method. However before calling removeAt, it would find the index of the element that needed to be removed. If we had two Tani nodes in our collection only the first one would be removed. That might not be the expected behavior we wanted. In this new implementation we pass the position of the node we want to remove, and voila! its gone. Let’s see how to do that by first looking at the diagram (remember these will give you better visualization).
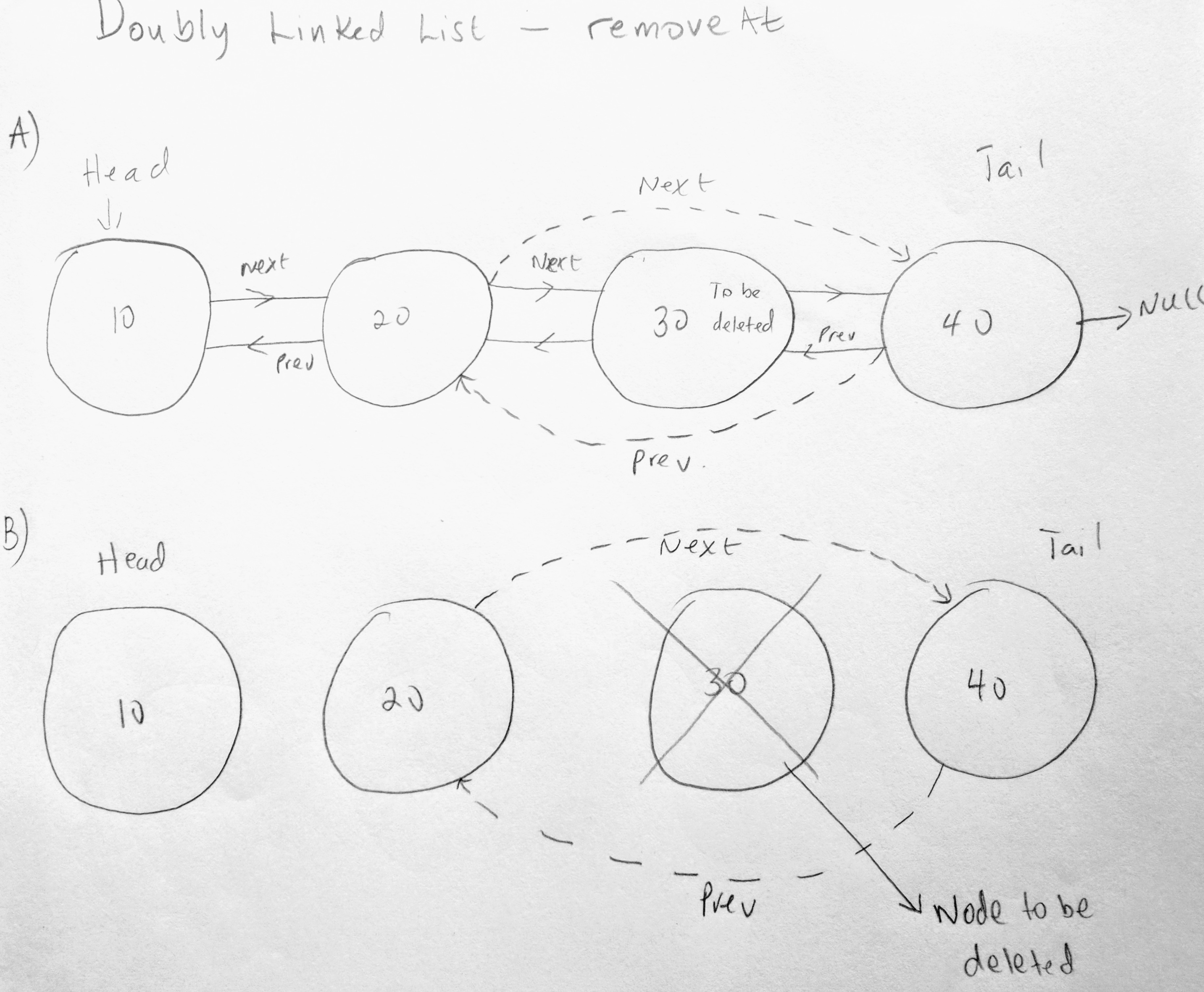
To get a better picture of what is going on, please look at the removeAt & removeAt from the previous post. In this diagram, two scenarios are stripped out. Removing from the head and from the tail. When removing nodes from a collection there are 3 possible things that could happen. Either we are removing from the head, tail or in between. The above diagram demonstrate removing nodes in between. Since we have already implement removeHead and removeTail, there is no need to speak of them here. You will see this in the code however.
Normally what happens is you have a collection and you want to remove a node at a specific position. In the diagram about notice we have a node marked for deletion (to be deleted). When we delete the node all we need to do is change the pointers of the nodes before and after. That is it. As you can see above node 20’s next will now be 40 and not 30 (since its marked for deletion). And node 40’s previous will now be 20. You get where i am going with this. Lets see the code to do this ( very similar to our enhance insert on this time we are removing a node from the collection).
See the Pen Doubly Linked List Remove by kofi (@scriptonian) on CodePen.
Everything here should be pretty clear to you by now. The only new part is changing the pointers for removeAt. All i did was look at the diagram. The next pointer of the position nodes previous is now the position nodes next. And the previous pointer of the position nodes next is the position nodes previous. After i set the pointers of the position node to null (since it is not needed. Will be garbage collected). Then i return the position node to the caller. This is not a necessary step. But sometime i like to know i deleted the right node, so this function returns to me the node that was deleted. Just so i know.
Thats it folks! I believe i have covered everything. If there is a method i didn’t cover here, for eg display, size, etc thats because the implementation is the same as that of a singly linked list. We only covered the necessary changes needed when moving from singly to doubly implementations. If you feel i left a method out, kindly let me know. I have seen other methods like displaying the collection in reverse. I didn’t feel that was challenging to do, so i left it out. Lets complete our linked list implementations by looking at circular linked lists (this will be a very short post and you are DONE with linked lists in javascript).
Do give me your feedback on how you have implemented some of your linked lists. I will surely like to learn from you as well. Feel free to reach out on twitter as well ( @scriptonian ) if you have any questions. Happy coding!
Hi Kofi,
Theory wise you shown the difference for singly and doubly linked list, but there was no difference in code wise which you have github.
Also singly Linked list also holds next and previous elements, then whats the exact difference between in both.
Thanks for the great info about advanced scripts
Govardhan, i will take a look shortly and get back to you. Perhaps i missed pushing something up 🙂